PERSONAL KNOWLEDGE
ENGINE.
The Challenge
Information overload kills productivity. Articles, threads, and insights get bookmarked and forgotten. Traditional note-taking requires manual organization. Knowledge workers need instant recall without the cognitive overhead of searching through scattered files.
The System
A two-workflow automation that turns Slack into an intelligent knowledge repository. Workflow one handles ingestion—it detects URLs vs. text, scrapes web content, strips HTML noise with Gemini AI, and stores clean markdown embeddings in Pinecone. Workflow two provides conversational access through a RAG-powered chat interface using Gemini 2.5 Pro.
THE ARCHITECTURE
Ingestion Pipeline
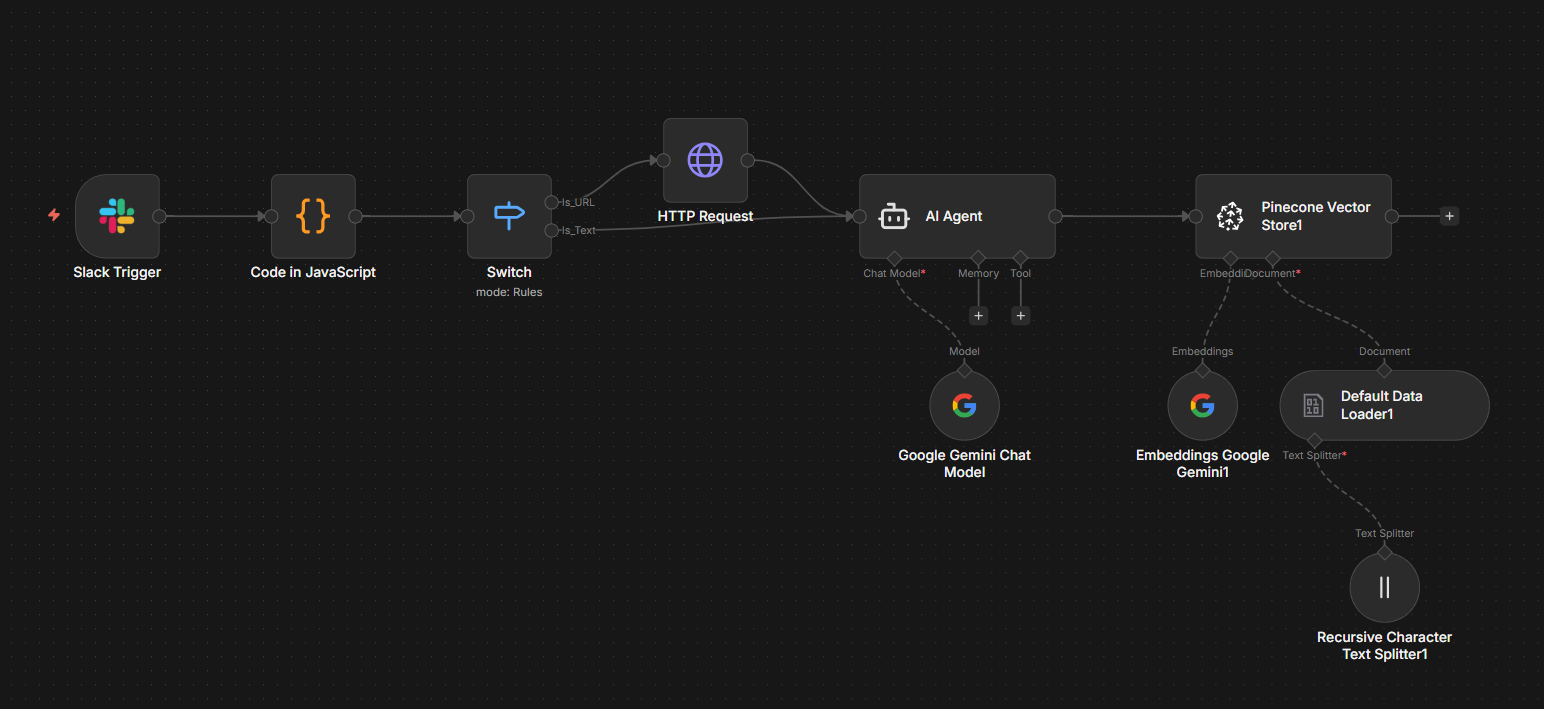
1. Slack Trigger
Monitors a dedicated Slack channel for incoming content. Acts as the universal input interface for both URLs and raw text.
2. JavaScript Parser
Distinguishes between URLs and pasted text using regex pattern matching. Routes each type to the appropriate processing branch.
3. HTTP Request
Fetches full webpage content for URLs. Handles redirects and extracts complete HTML for AI processing.
4. AI Agent (Gemini)
Strips formatting, removes navigation elements, and preserves core meaning. Converts messy HTML into clean, semantic markdown.
5. Recursive Text Splitter
Chunks content into optimal-sized segments for vector embedding. Maintains semantic coherence across splits.
6. Pinecone Vector Store
Indexes embeddings for semantic search. Each chunk becomes queryable through natural language without exact keyword matching.
Query Interface
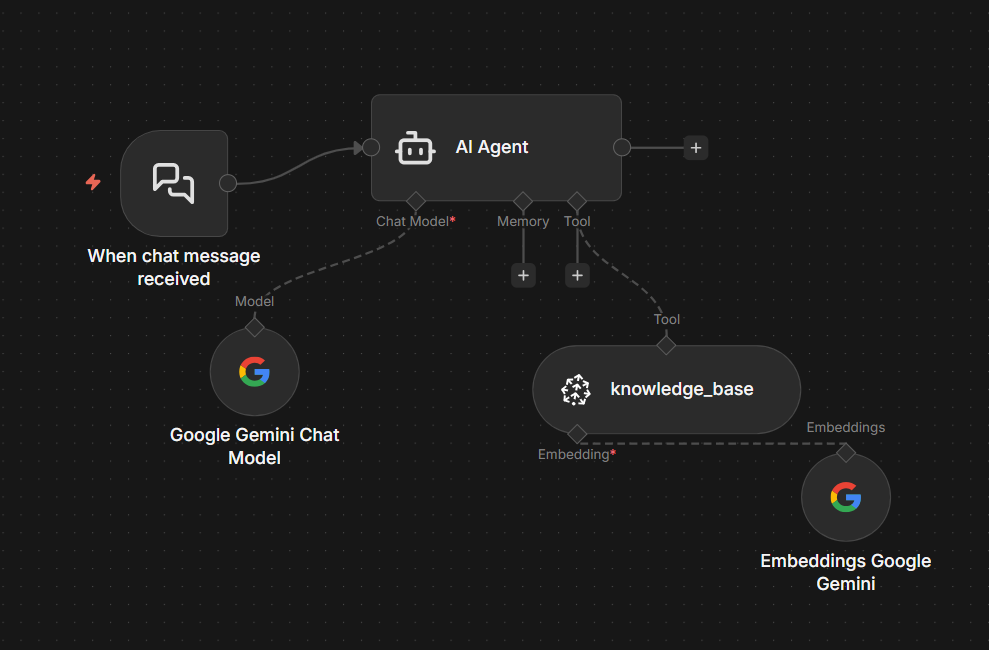
1. Chat Trigger
Receives natural language questions through the Slack interface. No special syntax or commands required.
2. Vector Retrieval
Searches Pinecone for the top 5 most relevant chunks based on semantic similarity. Bypasses traditional keyword matching limitations.
3. Gemini 2.5 Pro
Synthesizes retrieved chunks into coherent, contextualized answers. Acts as the reasoning layer over retrieved knowledge.
4. RAG Architecture
Ensures responses cite actual saved content rather than hallucinating. Grounds every answer in your documented knowledge base.
THE TECH STACK
n8n
Orchestration layer for both ingestion and query workflows. Handles conditional routing, error handling, and integration logic.
Gemini API
Powers content cleaning during ingestion and conversational responses during queries. Dual-purpose AI layer.
Pinecone
Vector database for semantic search. Enables natural language queries without relying on exact keyword matches.
Slack
User-facing interface for both ingestion and queries. Eliminates the need for separate dashboards or applications.
Drop a link or paste text into Slack—the system handles cleaning, chunking, and indexing automatically.
Query your knowledge base conversationally without remembering exact keywords or file locations.
THE OUTCOME
Zero-friction knowledge capture. Drop a link or paste text into Slack—the system handles the rest. Query your personal knowledge base conversationally without remembering where you saved something or how you tagged it.
The system eliminates the gap between saving information and retrieving insights. No manual categorization. No folder hierarchies. No cognitive overhead. Just instant, contextualized recall from your second brain.